লাইব্রেরি ইনস্টল
pip install requests
pip install bs4
pip install lxml
pip install pandasযেভাবে ব্যবহার করবো ?
import requests
from bs4 import BeautifulSoupHTML স্ক্র্যাপিং
লিংকের ওয়েবসাইট এ যাই ওয়েবসাইটি দেখতে নিচের মত :
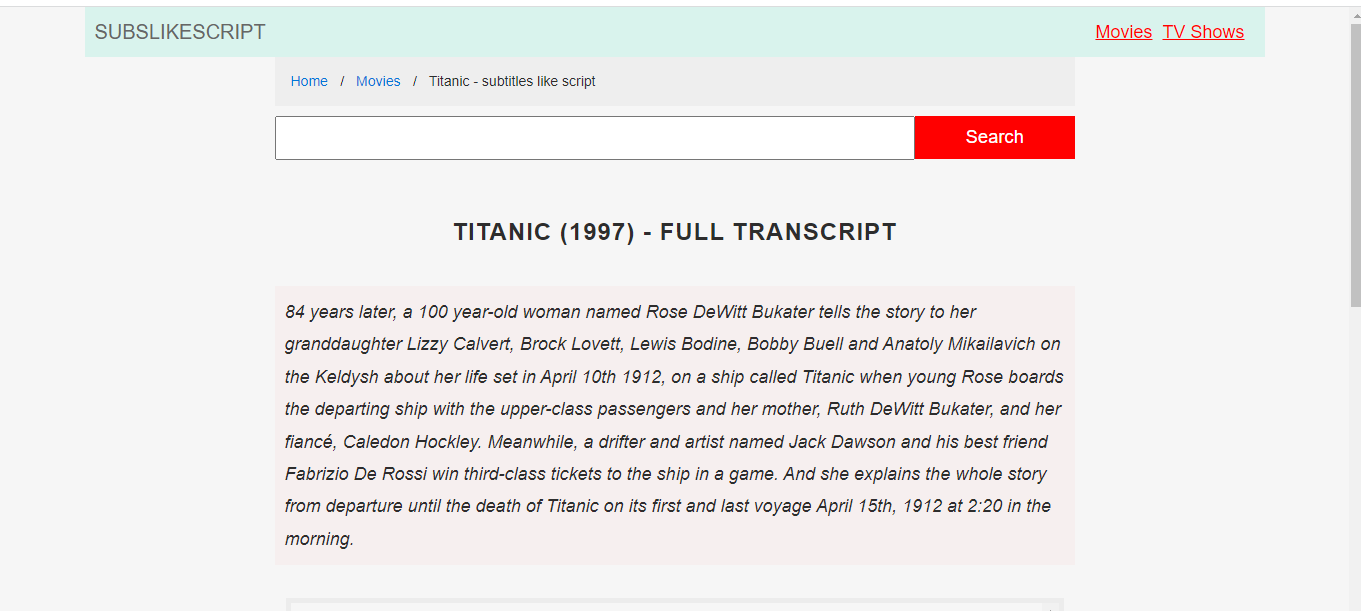
ওয়েবসাইট ইন্সপেক্ট করি তাহলে নিচের মত html স্ট্রাকটার পাবো
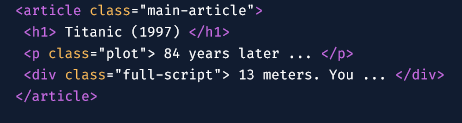
স্ট্রাকটার বোঝার চেষ্টা করি :
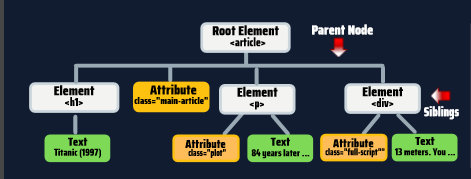
যেভাবে সিলেক্ট করবো :

Find Method
# Finding by id
s = soup.find('div', id= 'main')
# Finding by class
s = soup.find('div', class_='entry-content')
#find all
lines = s.find_all('p')
# Extracting Text from the tags
lines = s.find_all('p')
for line in lines:
print(line.text)
#Scrape Nested Tags using BeautifulSoup
soup.body.table.tag